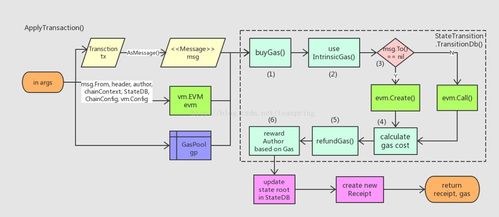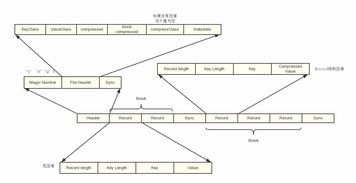
随着大数据技术的飞速发展,高效的数据存储与处理成为关键。不同的文件格式和数据处理服务,共同构成了大数据生态系统的基石。本文将介绍几种常用的大数据文件格式,并概述主流的数据处理与存储支持服务。
一、 常用大数据文件格式
- 文本格式
- CSV/TSV:以逗号或制表符分隔的纯文本文件,结构简单,兼容性极强,是人类可读的格式。但其缺乏模式定义,解析效率较低,且不支持复杂数据类型,通常用于数据交换或临时存储。
- JSON:基于JavaScript的轻量级数据交换格式,采用键值对结构,支持嵌套和复杂数据类型,具有良好的可读性。由于其解析成本较高且存储冗余,常用于Web API和半结构化数据存储。
- 行列存储格式
- Apache Parquet:一种面向列的存储格式,专为高效查询和处理大规模数据集而设计。它提供了高效的压缩和编码方案,能显著减少I/O操作,特别适合执行聚合查询的OLAP场景,是Hadoop/Spark生态系统的首选列式格式。
- Apache ORC:另一种高效的列式存储格式,最初为Hive设计。它在压缩率、读写性能和ACID事务支持方面表现优异,特别适合Hive数据仓库。
- Apache Avro:一种基于行的数据序列化系统,强调数据交换。它使用JSON定义模式,将模式与数据一同存储,支持动态模式演化,非常适合RPC和数据流场景。
- 其他优化格式
- Apache Arrow:并非一种持久化存储格式,而是一种内存中的列式数据格式标准,旨在实现不同系统间零拷贝的高性能数据交换,极大提升了内存计算效率。
选择哪种格式,取决于具体场景:列式格式(如Parquet)适合分析查询;行式格式(如Avro)适合需要访问整条记录的流处理;文本格式(如JSON)则更适合数据交换和灵活模式。
二、 数据处理与存储支持服务
数据处理与存储并非孤立存在,它们依赖于强大的底层服务。这些服务主要分为两大类:
1. 分布式存储服务
这些服务提供了可靠、可扩展的底层存储,是数据湖或数据仓库的基石。
- Hadoop Distributed File System:经典的分布式文件系统,具有高容错性,能以流式访问超大规模数据集,是早期大数据生态的核心存储。
- 云对象存储服务:如Amazon S3、阿里云OSS、腾讯云COS等。它们提供了近乎无限的存储空间、高持久性和按需付费模式,已成为现代数据湖架构的事实标准存储层,可与各类计算引擎无缝集成。
2. 数据处理与计算服务
这些服务在存储层之上,提供数据的计算、加工和分析能力。
- 批处理框架:以Apache Spark为代表,支持内存计算,能够高速处理海量数据的ETL、批分析和机器学习任务。Apache Flink同样强大,并以其流批一体的架构著称。
- 查询引擎:如Presto/Trino、Apache Hive,它们允许用户使用SQL或类SQL语言直接对存储在HDFS或对象存储中的大规模数据进行交互式查询。
- 流处理服务:专为处理无界数据流设计,如Apache Kafka(消息队列,常作为流数据管道)、Apache Flink和Apache Storm,能实现低延迟的实时数据处理。
- 托管服务:云厂商提供了全托管的服务以简化运维,例如Amazon EMR、阿里云EMR(托管Hadoop/Spark集群)、Google BigQuery(无服务器数仓)、Snowflake(云原生数仓)等。这些服务将计算与存储分离,提供了极佳的弹性和易用性。
三、 与趋势
在现代大数据架构中,云对象存储常作为统一的数据湖存储层,存储着Parquet、ORC等格式的原始或加工后的数据。Spark、Flink等计算框架则从存储中读取数据进行处理,处理结果再写回存储。Presto等查询引擎可对这些结果进行即席分析。整个过程由Kafka等流处理组件保障实时性,并由云上的托管服务简化管理。
未来的趋势是存储与计算的进一步分离、格式的持续优化(如更好地支持谓词下推和压缩),以及数据处理服务向无服务器化、智能化和实时化演进,使得企业能够更敏捷、更经济地从海量数据中提取价值。